
Dank OCR wird aus einem Scan ein Textdokument oder ein durchsuchbares PDF. ABBYY ist auf dem Markt für OCR-Software bereits seit vielen Jahren vertreten, konzentriert sich aber auf Windows-Systeme. Der erste Versuch einer Mac- Portierung konnte besonders Nutzer der Windows- Version nicht überzeugen: Die FineReader Express Edition bot nur wenig Nachbearbeitungsfunktionen und verließ sich ganz auf ABBYYs gute OCR-Routinen.
Neustart
FineReader OCR Pro ersetzt die Express Edition, die nicht mehr vertrieben wird und auch nicht an Mavericks angepasst wurde. Der Funktionsumfang wurde in allen Bereichen erweitert, komplizierter geworden ist die Bedienung dadurch aber nicht. Wer sich nicht weiter mit der Nachbearbeitung beschäftigen möchte, nutzt die Schnellkonvertierfunktion im Startdialog, mit der sich Scans schnell in Word-, PDF-, HTML- oder Excel-Dokumente umwandeln lassen. Das sind nicht alle unterstützten Ausgabeformate, FineReader kann ePub, RTF, OpenOffice (ODT), PowerPoint und reine Texte erzeugen.
Alle gängigen Bildformate und auch PDFs lassen sich importieren, das DjVu-Format wird nicht unterstützt.
Oberflächliches
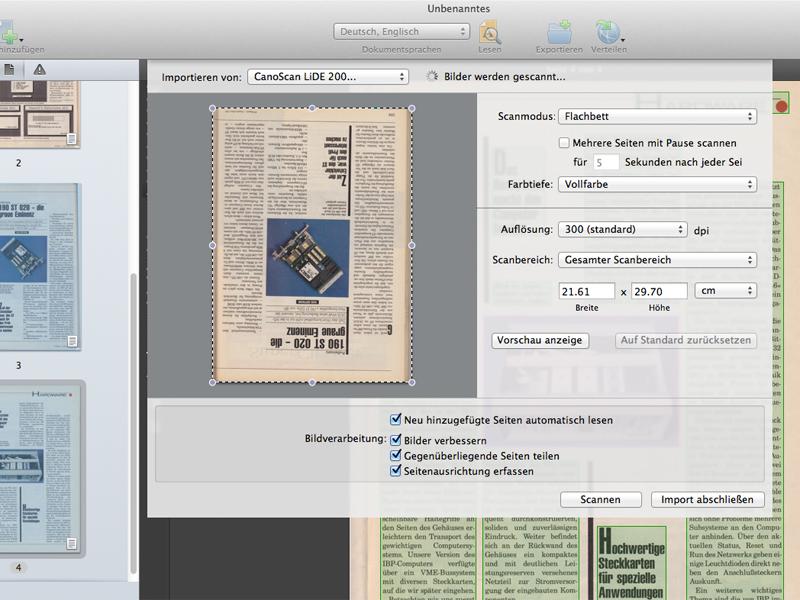
Wurde FineReader mit Bildern oder Scans versorgt, wird automatisch die Erkennung der Bereiche sowie die Texterkennung gestartet. Dabei erscheinen auch Warnungen, wenn die Auflösung zu niedrig für eine gute OCR ist.
Im Hauptfenster werden neue Bereiche (Text, Tabelle, Grafik, Hintergrundbild, Strichcodes) gezeichnet oder bestehende entfernt, neu sortiert oder verschmolzen. Bei mehrspaltigen, von Bildern unterbrochenen Seiten kann es vorkommen, dass die Bereiche nicht richtig nummeriert sind. Falls ein PDF ausgegeben wird, ist dies nicht relevant, da das Layout der Ursprungsseite übernommen und der erkannte Text von dem gescannten Bild überlagert wird.
Die Benutzeroberfläche orientiert sich mit ihrer Dreiteilung in Seitenleiste, Anzeigebereich und Inspektor an der Express Edition, der Windows- FineReader setzt hingegen auf die von Office bekannte Ribbon-Oberfläche. Die Funktionen sind anders sortiert, aber größtenteils identisch, die Anpassung an den Mac ist gelungen.
Texterkennung
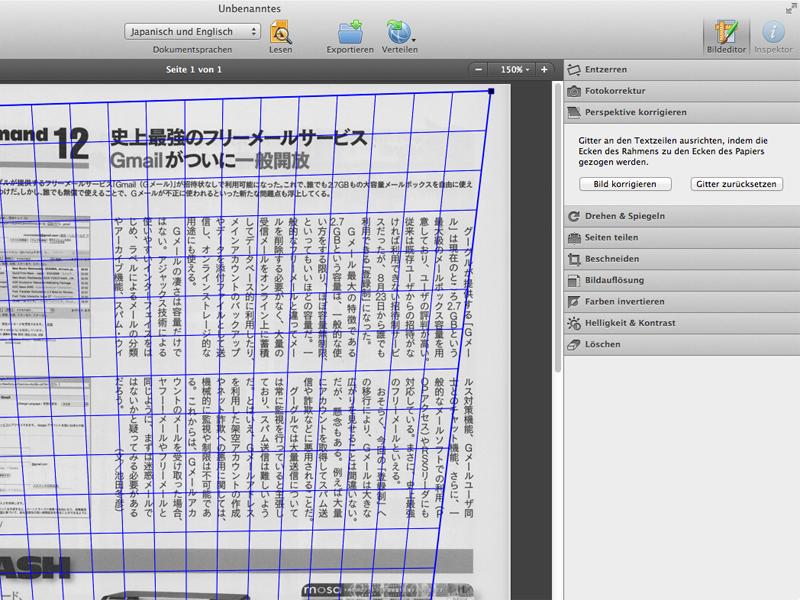
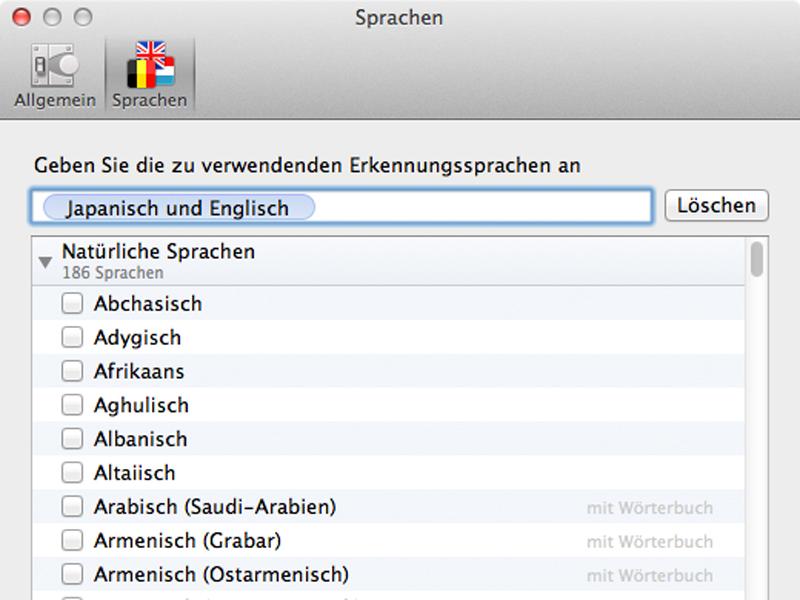
Im Vergleich zur Express Edition hat FineReader Pro bei den unterstützten Sprachen dazugelernt: Mehr als 180 Sprachen werden unterstützt, inklusive Dialekten und einigen Programmiersprachen. Darunter sind auch viele Sprachen, die nicht auf dem lateinischen Alphabet basieren, beispielsweise Hebräisch oder Koreanisch. Anspruchsvoll für die OCR ist die japanische Sprache, die neben chinesischen Schriftzeichen zwei Silbenschriften verwendet. Oft tauchen auch lateinische Buchstaben in Texten auf, außerdem werden in Magazinen und Zeitschriften auf einer Seite häufig Textrichtungen gemischt. Dagegen ist die englische Sprache für die OCR anspruchslos: Ein Schriftsystem und keine Umlaute, wer hauptsächlich englischsprachige Dokumente scannt, braucht keine professionelle OCR-Lösung.
Getestet wurde FineReader Pro mit Texten in deutscher, japanischer und koreanischer Sprache. Das OCR-Ergebnis für gescannte Seiten einer japanischen Mac-Zeitschrift konnte überzeugen, die unterschiedlichen Textrichtungen und Schriftgrößen wurden korrekt erkannt. Wenn FineReader während der Texterkennung Warnungen ausgibt, lohnt sich ein Blick auf die erkannten Bereiche, denn Screenshots auf den gescannten Seiten wurden zum Teil fälschlich als Textbereiche erkannt. Solche Bereiche sollten dann in Grafikbereiche umgewandelt werden.
Ebenso wenig Probleme hatte FineReader mit Texten in koreanischer und deutscher Sprache, sofern die Scans mindestens in 300dpi vorliegen,gibt es kaum Fehler bei der OCR, selbst wenn mehrere Sprachen auf einer Seite gemischt werden. Einzig Absätze und Trennzeichen erfordern nach dem Textexport eine manuelle Korrektur.
Bei geringerer Auflösung oder nicht optimaler Bildqualität zeigen sich typische Fehler wie falsch erkannte Umlaute (à wird zu ä), Buchstaben, die verschmelzen, und Probleme bei der Unterscheidung zwischen 0 (Null) und O. Eine Lernfunktion, um der OCR eine bestimmte Schriftart beizubringen und OCR-Fehler noch im Programm zu korrigieren, gibt es nicht. Leider ist im Hauptfenster auch nicht ersichtlich, welche Bereiche des Dokuments für die Texterkennung problematisch waren. Ohne Export lässt sich nur anhand der Sauberkeit der markierten Bereiche abschätzen, wie gut die Texterkennung geklappt hat.
- Seite 1: Test: ABBYY FineReader für OS X
- Seite 2: Bildeditor




Diskutiere mit!
Hier kannst du den Artikel "Test: ABBYY FineReader für OS X" kommentieren. Melde dich einfach mit deinem maclife.de-Account an oder fülle die unten stehenden Felder aus.
Die Kommentare für diesen Artikel sind geschlossen.